Overview
Simulation
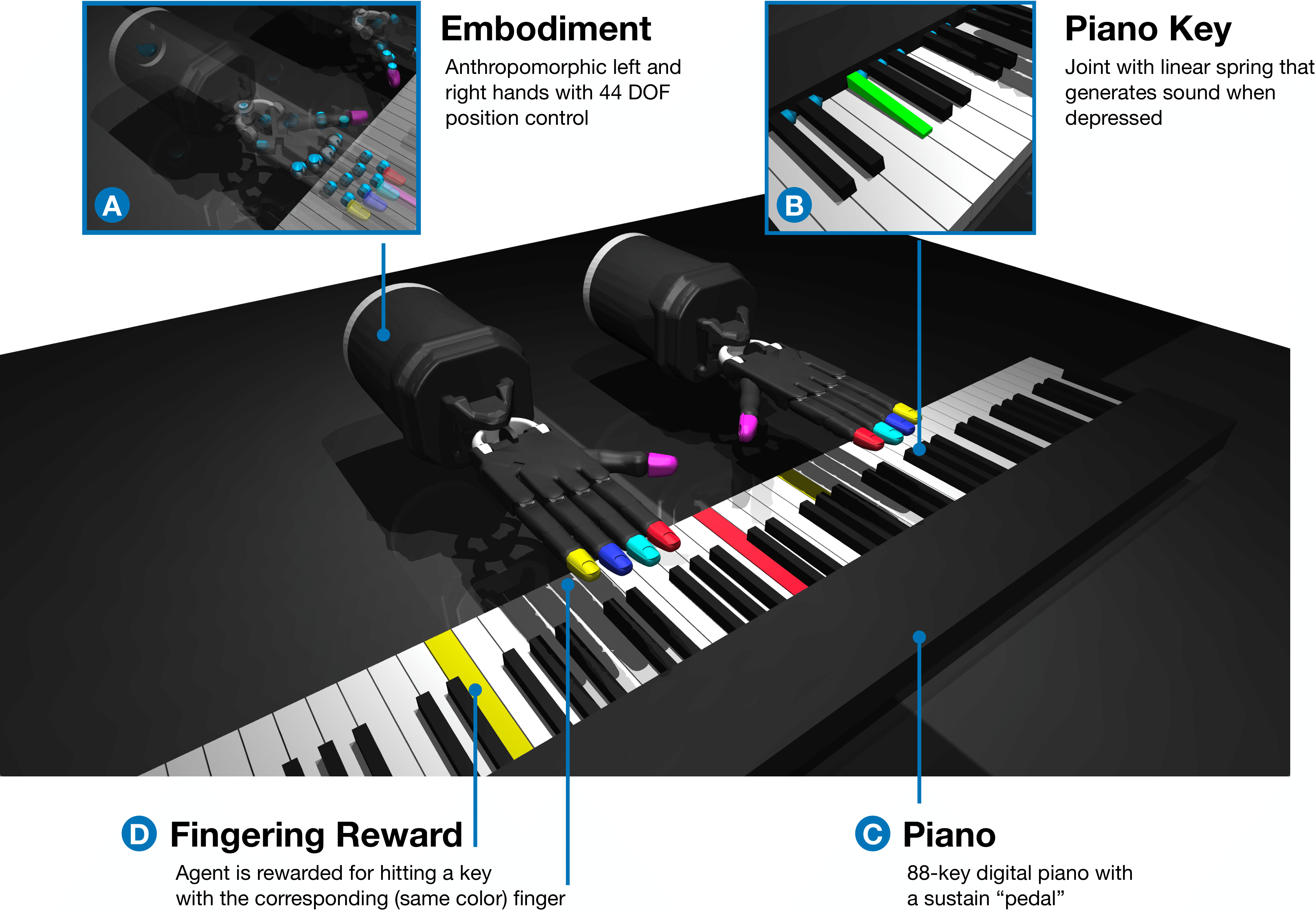
We build our simulated piano-playing environment using the open-source MuJoCo physics engine. It consists in a full-size 88-key digital keyboard and two Shadow Dexterous Hands, each with 24 degrees of freedom.
Musical representation
We use the Musical Instrument Digital Interface (MIDI) standard to represent a musical piece as a sequence of time-stamped messages corresponding to "note-on" or "note-off" events. A message carries additional pieces of information such as the pitch of a note and its velocity.
We convert the MIDI file into a time-indexed note trajectory (also known as a piano roll), where each note is represented as a one-hot vector of length 88 (the number of keys on a piano). This trajectory is used as the goal representation for our agent, informing it which keys to press at each time step.
The interactive plot below shows the song Twinkle Twinkle Little Star encoded as a piano roll. The x-axis represents time in seconds, and the y-axis represents musical pitch as a number between 1 and 88. You can hover over each note to see what additional information it carries.
A synthesizer can be used to convert MIDI files to raw audio:
Musical evaluation
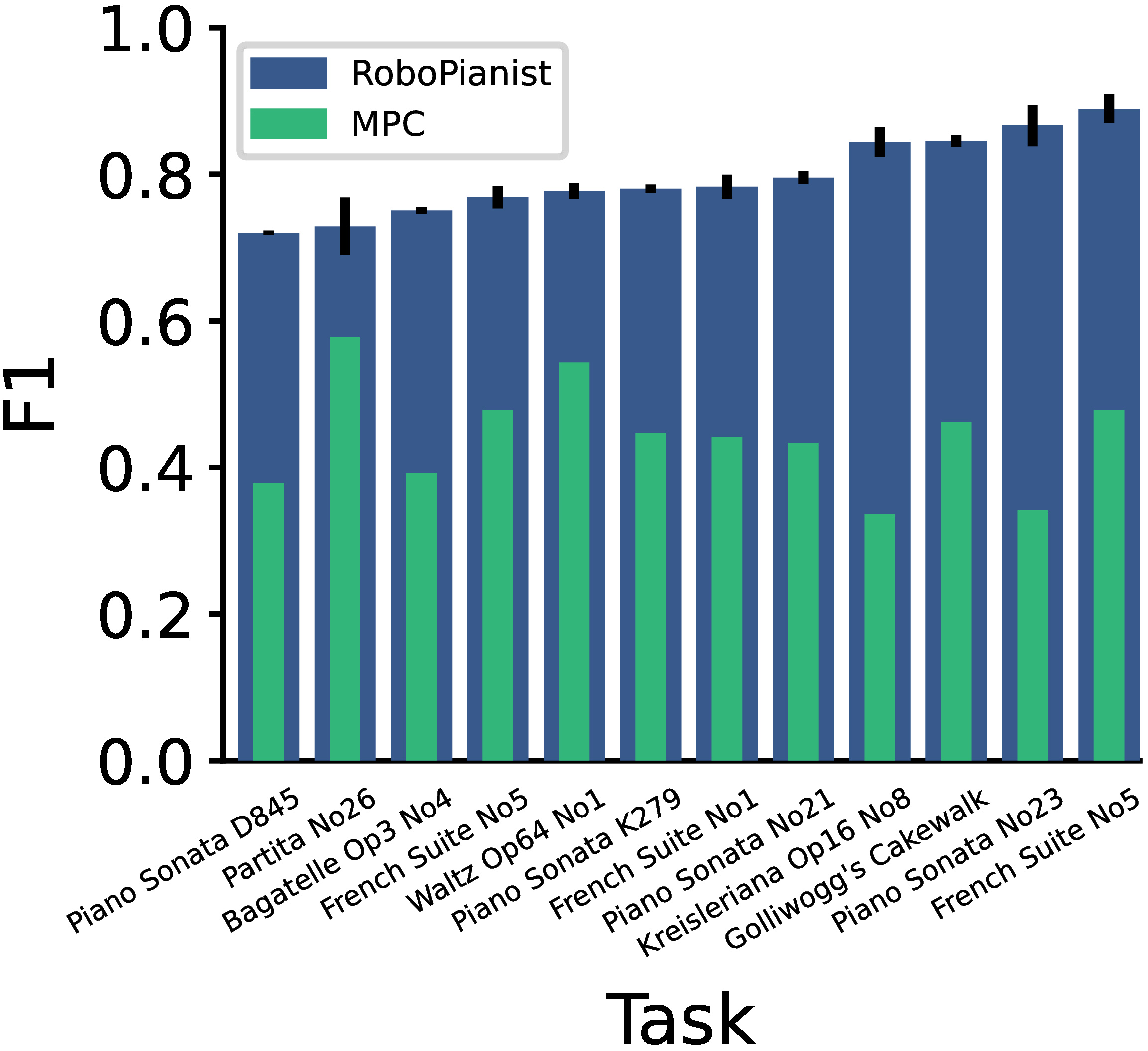
We use precision, recall and F1 scores to evaluate the proficiency of our agent. If at a given instance of time there are keys that should be "on" and keys that should be "off", precision measures how good the agent is at not hitting any of the keys that should be "off", while recall measures how good the agent is at hitting all the keys that should be "on". The F1 score combines the precision and recall into a single metric, and ranges from 0 (if either precision or recall is 0) to 1 (perfect precision and recall).
Piano fingering and dataset
Piano fingering refers to the assignment of fingers to notes in a piano piece (see figure below). Sheet music will typically provide sparse fingering labels for the tricky sections of a piece to help guide pianists, and pianists will often develop their own fingering preferences for a given piece.
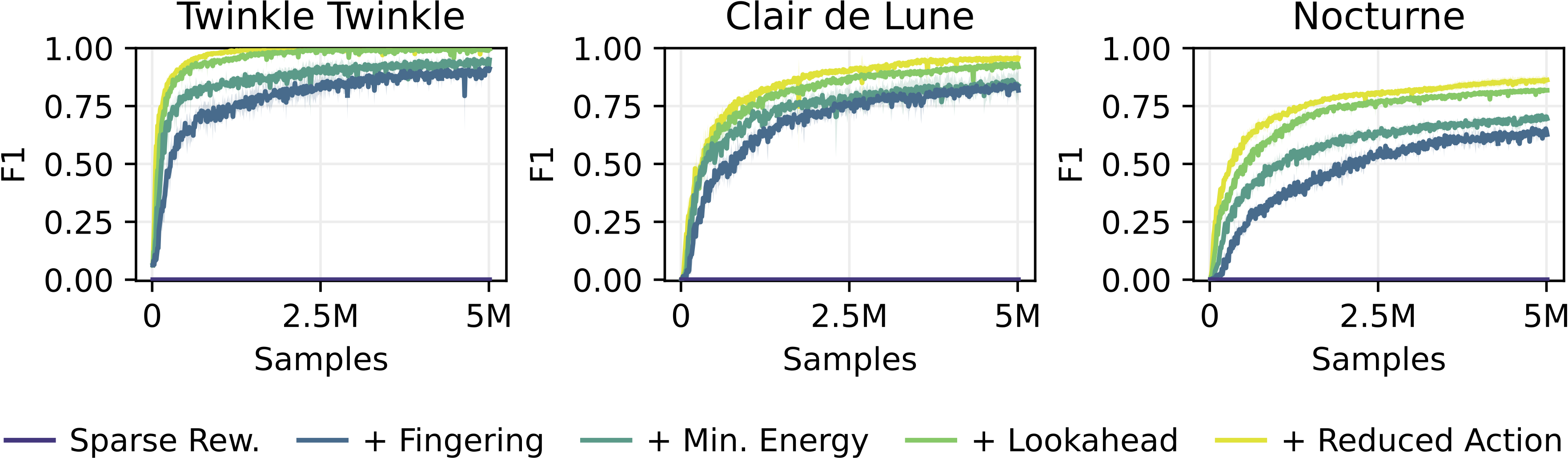
In RoboPianist, we found that the agent struggled to learn to play the piano with a sparse reward signal due to the exploration challenge associated with the high-dimensional action space. To overcome this issue, we added human priors in the form of the fingering labels to the reward function to guide its exploration.
Since fingering labels aren't available in MIDI files by default, we used annotations from the Piano Fingering Dataset (PIG) to create 150 labeled MIDI files, which we call Repertoire-150 and release as part of our environment.

MDP Formulation
We model piano-playing as a finite-horizon Markov Decision Process (MDP) defined by a tuple \( (\mathcal{S}, \mathcal{A}, \mathcal{\rho}, \mathcal{p}, r, \gamma, H) \), where \( \mathcal{S} \) is the state space, \( \mathcal{A} \) is the action space, \( \mathcal{\rho}(\cdot) \) is the initial state distribution, \( \mathcal{p} (\cdot | s, a) \) governs the dynamics, \( r(s, a) \) is the reward function, \( \gamma \) is the discount factor, and \( H \) is the horizon. The goal of the agent is to maximize its total expected discounted reward over the horizon \( \mathbb{E}\left[\sum_{t=0}^{H} \gamma^t r(s_t, a_t) \right] \).
At every time step, the agent receives proprioceptive (i.e, hand joint angles), exteroceptive (i.e., piano key states) and goal observations (i.e., piano roll) and outputs 22 target joint angles for each hand. These are fed to proportional-position actuators which convert them to torques at each joint. The agent then receives a weighted sum of reward terms, including a reward for hitting the correct keys, a reward for minimizing energy consumption, and a shaping reward for adhering to the fingering labels.
For our policy optimizer, we use a state-of-the-art model-free RL algorithm DroQ and train our agent for 5 million steps with a control frequency of 20 Hz.